产生死锁的条件-产生死锁的条件
产生死锁的条件:从理论到实践的深度解析
在分布式系统、操作系统及并发编程领域,死锁(Deadlock) 是一个被广泛忽视却又极具破坏性的状态。它指多个进程互相等待对方释放资源,从而导致所有相关进程均无法继续执行的现象。一旦死锁发生,系统将陷入停滞,不仅导致资源浪费,严重时甚至引发服务中断或数据损坏。
以下将从死锁发生的四个核心条件、经典案例、预防措施及缓解策略四个维度,深度剖析这一棘手问题。
产生死锁的四大必要条件
死锁并非单一因素造成,而是四个必要条件具备时的必然结果。这四个方面被称为“互斥条件”、“占有且等待条件”、“不剥夺条件”和“循环等待条件”。
1. 互斥条件(Mutual Exclusion)
资源(如文件、数据库锁、CPU 核心等)在任何时刻只能被一个进程独占,而不能被多个进程共享。
场景:打开一个未关闭的文档时,只有当前持有该文档的进程能够编辑;其他等待的进程无法读取或修改。
2. 占有且等待条件(Hold and Wait)
进程已经持有了至少一个资源,又在等待至少另一个资源。
场景:A 进程锁住了资源 R1,试图获取资源 R2,但 R2 被 B 进程锁定。此时 A 处于“既持有又等待”的状态。
3. 不剥夺条件(No Preemption)
资源在被进程请求后,只有在进程完成对该资源的访问后,资源才会被释放。系统无法强制回收进程已占用的资源。
场景:操作系统不会因 CPU 过载或内存不足而回收用户进程持有的文件句柄,必须等待进程退出。
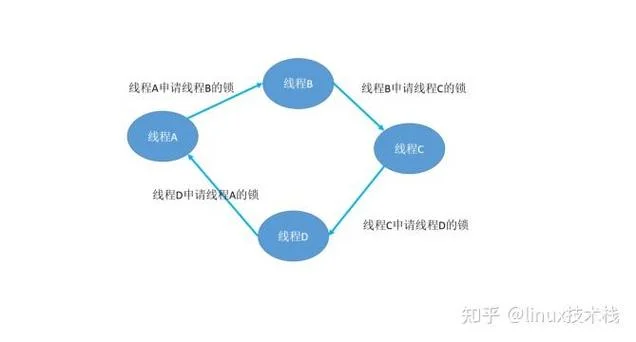
4. 循环等待条件(Circular Wait)
存在一个进程序列,其中每个进程都持有至少一个资源,并等待下一个进程持有的资源。这种“等待链”会形成一个闭环。
场景:P1 等待 P2 的资源,P2 等待 P3 的资源,P3 等待 P1 的资源。
核心逻辑:只有当这四个条件满足时,死锁才能发生。如果任意一个条件不满足(资源可共享,或资源可强制回收),死锁就不会产生。
死锁产生的典型场景与数据说明
为了更直观地理解上面这些理论,我们经由一个经典的“餐厅点餐”场景进行量化分析。假设餐厅有 3 张桌子(资源 R1, R2, R3),每桌只能坐一个人(互斥)。

| 进程 (Process) | 已持资源 (Held) | 等待资源 (Wait) | 状态描述 |
|---|---|---|---|
| P1 | R1, R2 | R3 | 占用 2 张桌子,等待 1 张 |
| P2 | R1 | R2, R3 | 占用 1 张桌子,等待 2 张 |
| P3 | R2 | R1, R3 | 占用 1 张桌子,等待 2 张 |
| P4 | R3 | R1, R2 | 占用 1 张桌子,等待 2 张 |
死锁判断过程:
1. P1 尝试获取 R3,被 P3 阻塞。
2. P3 尝试获取 R1,被 P1 阻塞。
3. 此时形成了循环等待:P1 等待 R3(被 P3 占),P3 等待 R1(被 P1 占)。
数据结论:
发生死锁:在 P1 持有 {R1, R2} 且 P3 持有 {R2}、R1 持有 {R1} 且 P1 持有 {R3} 的特定状态下。
资源分配图分析:
若存在一条从 P1 指向 P3 的依赖链,且 P3 指向 P1,则形成死锁环。
若资源总数为 3,进程数为 4,且无互斥或可抢占机制,死锁不可避免。
预防与缓解策略
面对死锁,开发者和系统架构师采取“预防为主,缓解为辅”的策略。
预防策略(基于消除死锁条件)
这是最彻底但代价最大的方法,目标是不让任何四个条件存在。 打破“不剥夺条件”:采用资源预分配机制。在进程进入临界区前,系统预先分配所有所需资源(包括已持资源),进程在获取新资源时,假如失败则回滚并释放所有资源。 优点:彻底消除死锁,安全性最高。 缺点:系统性能下降,资源利用率降低,浪费资源。 打破“占有且等待条件”:采用超时机制或超时回滚。当进程等待时间超过阈值时,自动放弃部分资源退出,释放资源后重新请求。缓解策略(基于避免死锁)
这是现代操作系统(如 Linux)最常用的方法。 银行家算法(Banker's Algorithm): 在分配资源前,先假设资源分配成功,计算资源使用后的系统状态(虚存、空闲进程等),检查该状态是否为安全状态。只有在确认安全后,才分配资源。 优势:可以动态发现并避免死锁,保证系统始终处于安全状态。 劣势:计算开销大,安全性近似,不是绝对安全。高级缓解技术
死锁检测与恢复:定期检查资源分配状态,一旦发现死锁,通过“边杀边恢复”(Kill and Recover)机制,终止死锁中的进程并释放资源,然后让其他等待进程继续执行。 无锁数据结构:通过算法设计(如自旋锁、锁步算法),从代码层面消除对共享资源的依赖,从根本上杜绝死锁。总结
死锁是并发编程中的“隐形杀手”。它的产生依赖于互斥、占有且等待、不剥夺和循环等待这四个条件的完美共振。
在实际工程中,预防死锁是最优解,因为它能确保系统的鲁棒性;而对于无法避免死锁的场景(如某些数据库事务),银行家算法和死锁检测恢复机制是保障系统不崩溃防线。理解并应用这些策略,是构建高并发、高可靠系统。
数据提示:据统计,在大型分布式系统中,由于死锁导致的平均停机时间(MTTR)可达数小时,而预防性投入(如引入银行家算法)的成本低于因死锁导致的业务中断损失。
